If you are new to supercomputing, this page will guide you through the basic steps and concepts needed to interact with a supercomputer.
What is a supercomputer?
Most science experiments today involve executing computer programs to produce or analyse data. For instance, computational analysis is used to determine genetic changes within tumours; another example is the analysis of the large amount of observational data produced by a radio telescope to discover signals from extraterrestrial sources. Ordinary workstations or laptops are not able to satisfy the computational demand of these analyses. For this reason governments and, increasingly, private companies build large-scale computing infrastructures - supercomputers - to meet the ever-increasing compute needs of the scientific community.
A supercomputer is a very complex hardware and software infrastructure comprising thousands of compute nodes, comparable to high-end desktop computers, connected together via a high-speed network, the interconnect. Compute nodes are equipped with powerful CPUs, a large amount of memory and often with hardware accelerators such as Graphics Processing Units (GPUs) to carry on specialised operations. In addition, sophisticated storage infrastructures, that support the distributed filesystems accessible from all compute nodes, allow for reading and writing large volumes of data at a high rate. Where computing performance can be measured in floating-point operations per second (FLOPS), a supercomputer can achieve dozens or hundreds of petaFLOPS (one petaFLOPS is a quadrillion FLOPS). It does this by executing code in parallel across the many compute units—CPUs and accelerators—that are available. A computer program must be written using parallel programming frameworks, enabling computational work to be distributed across CPU cores, to exploit the computational bandwidth of a supercomputer.
Supercomputer architecture
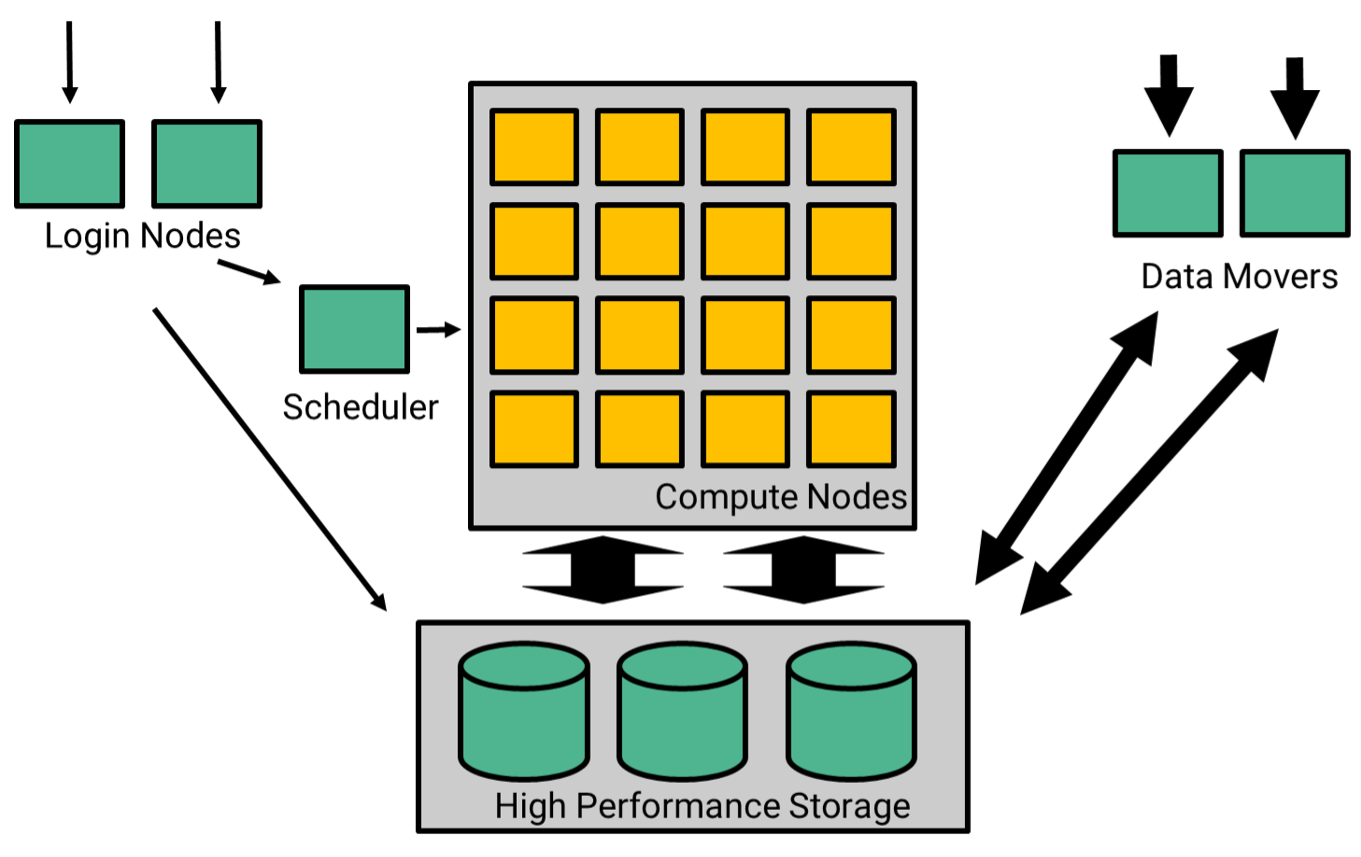
From the user perspective, a supercomputer includes the following components:
- Login nodes. These are remote hosts users connect to in order to interact with the supercomputer. From a login node, you are able to launch applications on compute nodes, monitor the status of your computations, and work on scripts, source code and configuration files.
- Compute nodes, where user programs actually run. There are hundreds of compute nodes equipped with high-end CPUs, a large quantity of RAM, and possibly GPUs to enable accelerated computing. Setonix makes heavy use of GPU nodes.
- Scheduler. Users do not get access to computing resources immediately. Instead, they describe their computational requirements and programs to execute, together forming a user job, to a special program called a scheduler. The scheduler then grants user jobs access to compute nodes as soon as they become available, according to a priority list.
- High-Performance Storage. A high-performance filesystem is where data is read from and written to on a supercomputer by a running job. Compared to classic filesystems found on workstations, they provide fast access to a large pool of storage devices that is uniform and consistent across all compute nodes. Long term storage enables users to save their data for later use and sharing.
- Data mover nodes are compute nodes designed to execute large transfers of data to and from the filesystems of a supercomputer.
To learn more about supercomputers, look at the recording of Introduction to Supercomputers (Using Supercomputers Part 1 and Part 2 on YouTube), or register for the next training session.
Supercomputers at Pawsey
The computing resources available at Pawsey Supercomputing Research Centre are listed on the Resource Overview page.
In short, the Setonix supercomputer combines AMD CPUs and GPUs, based on the HPE Cray EX architecture. It has more than 200,000 CPU cores and 750 GPUs, interconnected using the Slingshot-10 interconnect with 200Gb/s bandwidth per connection. The AMD Infinity Fabric interconnect provides a direct channel of communication among GPUs as well as between CPUs and GPUs.
Supercomputing applications
Many users adopt existing, highly optimised software packages to run their analyses on a supercomputer. Supercomputing applications are able to use hundreds or thousands of CPU cores in parallel to support large-scale experiments that are impossible to execute on a desktop computer. The most popular applications are already available on Pawsey supercomputers, installed in such a way as to make the most out of the computing infrastructure. Users must use the Modules system to explore and use them. Other users write their own software often relying on Pawsey-provided scientific libraries and parallel programming frameworks such as OpenMPI and HIP. In either case, the use of efficient programs is strongly encouraged to maximise supercomputer utilisation and ultimately scientific outcomes.
Your first job
In this section, you are going to submit your first computation to Pawsey's latest supercomputer, Setonix. More precisely, the example you'll walk through is compiling and executing one of the codes used in the Introductory Supercomputing course: hello-mpi. The program simply generates multiple processes, each printing its own unique MPI rank (a process identifier).
Log into Setonix using your Pawsey account. If you use the command line on your laptop, you execute the following:
$ ssh <username>@setonix.pawsey.org.au
For more information about logging in, visit Connecting to a Supercomputer.After logging in, you'll find yourself in your home directory on the
/homefilesystem of the supercomputer. This is used mostly to store user configurations; to work on software and data, move to the/scratchfilesystem. In particular, each user has a directory located at/scratch/<projectcode>/<username>. For convenience, the environment variableMYSCRATCHcontaining that path is already defined. Here is an example of how to do it.Terminal 1. Moving to the scratch folder$ cd $MYSCRATCH $ pwd /scratch/projectxy/userz
To read more about supercomputing filesystems, head to File Management.
The code can be found on Pawsey's GitHub profile. You can download files on the supercomputer using login nodes (for small files) or data mover nodes. Once the repository is cloned, change the current work directory to the
hello-mpifolder.Terminal 2. Cloning a git repository$ git clone https://github.com/PawseySC/Introductory-Supercomputing.git Cloning into 'Introductory-Supercomputing'... remote: Enumerating objects: 46, done. remote: Counting objects: 100% (11/11), done. remote: Compressing objects: 100% (9/9), done. remote: Total 46 (delta 2), reused 9 (delta 2), pack-reused 35 Receiving objects: 100% (46/46), 206.28 KiB | 1.13 MiB/s, done. Resolving deltas: 100% (12/12), done. $ cd Introductory-Supercomputing/hello-mpi
The source code,
hello-mpi.ccan be compiled with the Cray C compiler, readily available in the environment through theccalias. It is strongly recommended to compile the code on compute nodes, so a script is written to submit a job to the scheduler such that the code is compiled and then executed. In the same folder, use an editor of your choice (for instance,nanoorvim) to write a script that looks like the following.Listing 1. An example of batch script#!/bin/bash #SBATCH --nodes=2 #SBATCH --ntasks-per-node=3 #SBATCH --partition=work #SBATCH --account=projectxy cc -o hello-mpi hello-mpi.c srun ./hello-mpi
Replace
projcodewith your project code. The script will first compile the code, then it will launch it on 2 nodes, creating 3 processes on each one of them. Thesruncommand is used to execute parallel and distributed applications.Use the
sbatchcommand to submit the script to the scheduler for execution.Terminal 3. Submitting the job$ sbatch script.sh Submitted batch job 1670
Once submitted, you can use the
squeuecommand to check the status of your job.Terminal 4. Checking the status of your job.$ squeue --me JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 1670 work script.s cdipietr R 0:02 2 nid[001008-001009]In this case, the command shows that the job is running, what nodes are being used and the elapsed time.
If the job is not displayed anymore in the
squeueoutput list, then it has terminated its execution. Thesacctcommand shows the details of past jobs, hence it can be used to verify whether the job ended correctly.Terminal 5. Demonstrating the use of sacct$ sacct JobID JobName Partition Account AllocCPUS State ExitCode ------------ ---------- ---------- ---------- ---------- ---------- -------- 1670 script.sh work projcode 8 COMPLETED 0:0 1670.batch batch projcode 4 COMPLETED 0:0 1670.extern extern projcode 8 COMPLETED 0:0 1670.0 hello-mpi projcode 8 COMPLETED 0:0The standard output and error streams are redirected to a file named
slurm-<jobID>.outthat is created in the same directory the job was submitted from.Terminal 6. The output of a slurm job is stored in a text file$ cat slurm-1670.out 0 of 6: Hello, World! 3 of 6: Hello, World! 1 of 6: Hello, World! 2 of 6: Hello, World! 4 of 6: Hello, World! 5 of 6: Hello, World!
For more information about submitting jobs and interacting with the scheduler, visit Job Scheduling.
You can also download the output file using a file transfer tool like
scp. For instance, if you use Linux or Mac, you can do the following on a terminal window on your machine.Terminal 7. Copying data from the supercomputer to a local machine$ scp data-mover@setonix.pawsey.org.au:/scratch/projectxy/userz/Introductory-Supercomputing/hello-mpi/slurm-1670.out . ############################################################################# # # # This computer system is operated by the Pawsey Supercomputing Centre # # for the use of authorised clients only. # # # # The "Conditions of Use" for Pawsey systems and infrastructure can be # # found at this publically visible URI: # # # # https://support.pawsey.org.au/documentation/display/US/Conditions+of+Use # # # # By continuing to use this system, you indicate your awareness of, and # # consent to, the terms and conditions of use defined in that document. # # # # If you do not agree to the terms and conditions of use as defined in # # that document, DO NOT CONTINUE TO ACCESS THIS SYSTEM. # # # # Questions about this system, access to it, and Pawsey's "Conditions of # # Use" should be addressed, by email, to: help@pawsey.org.au # # # ############################################################################# slurm-1670.out 100% 165 33.3KB/s 00:00 $
In this example we have used a data mover node. A data mover node is dedicated to large file transfers that would otherwise disrupt activities on login nodes.
What's next?
You will have to think about how to migrate your workflows from a local machine or cluster to a supercomputing environment. In many cases, you will need to consider the following:
- If you are using a third-party software, is it already available on the supercomputer or should you install it yourself? The Software Stack page might help you to answer this question.
- How to upload and store data? File Management contains the answer.
- What is the scale of the computation, and how to orchestrate it in such a way to comply with Slurm policies and constraints (for example, the wall time)? Check out Job Scheduling.
Our documentation covers many aspects of interacting with a supercomputer. Visit the landing page Supercomputing Documentation for an overview of the topics.
If you would like more information about running using the GPU resources, see Example Slurm Batch Scripts for Setonix on GPU Compute Nodes.